
Recent progress in AI largely boils down to one thing: Scale.
Around the beginning of this decade, AI labs noticed that making their algorithms—or models—ever bigger and feeding them more data consistently led to enormous improvements in what they could do and how well they did it. The latest crop of AI models have hundreds of billions to over a trillion internal network connections and learn to write or code like we do by consuming a healthy fraction of the internet.
It takes more computing power to train bigger algorithms. So, to get to this point, the computing dedicated to AI training has been quadrupling every year, according to nonprofit AI research organization, Epoch AI.
Should that growth continue through 2030, future AI models would be trained with 10,000 times more compute than today’s state of the art algorithms, like OpenAI’s GPT-4.
“If pursued, we might see by the end of the decade advances in AI as drastic as the difference between the rudimentary text generation of GPT-2 in 2019 and the sophisticated problem-solving abilities of GPT-4 in 2023,” Epoch wrote in a recent research report detailing how likely it is this scenario is possible.
But modern AI already sucks in a significant amount of power, tens of thousands of advanced chips, and trillions of online examples. Meanwhile, the industry has endured chip shortages, and studies suggest it may run out of quality training data. Assuming companies continue to invest in AI scaling: Is growth at this rate even technically possible?
In its report, Epoch looked at four of the biggest constraints to AI scaling: Power, chips, data, and latency. TLDR: Maintaining growth is technically possible, but not certain. Here’s why.
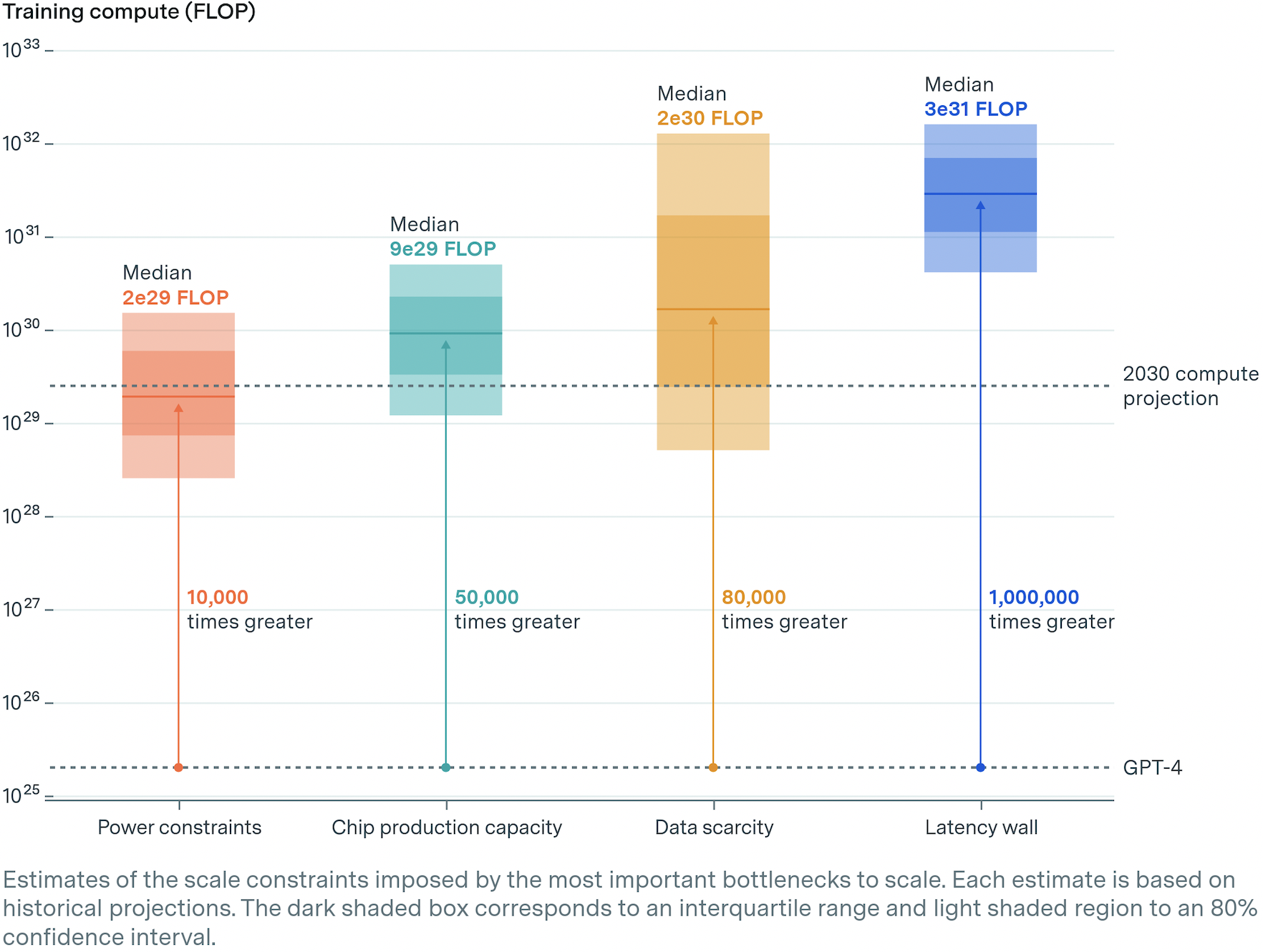
Power: We’ll Need a Lot
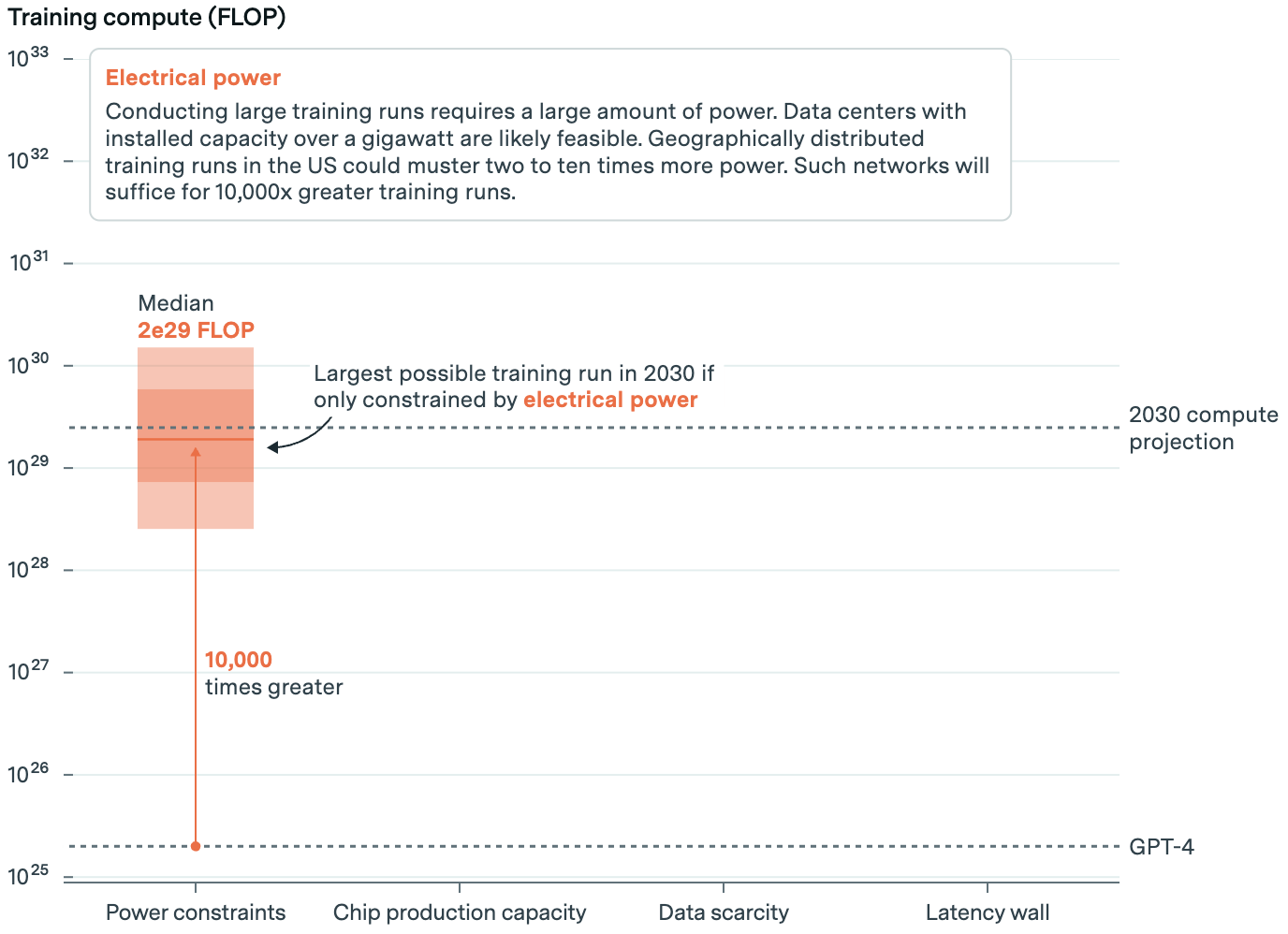
Power is the biggest constraint to AI scaling. Warehouses packed with advanced chips and the gear to make them run—or data centers—are power hogs. Meta’s latest frontier model was trained on 16,000 of Nvidia’s most powerful chips drawing 27 megawatts of electricity.
This, according to Epoch, is equal to the annual power consumption of 23,000 US households. But even with efficiency gains, training a frontier AI model in 2030 would need 200 times more power, or roughly 6 gigawatts. That’s 30 percent of the power consumed by all data centers today.
There are few power plants that can muster that much, and most are likely under long-term contract. But that’s assuming one power station would electrify a data center. Epoch suggests companies will seek out areas where they can draw from multiple power plants via the local grid. Accounting for planned utilities growth, going this route is tight but possible.
To better break the bottleneck, companies may instead distribute training between several data centers. Here, they would split batches of training data between a number of geographically separate data centers, lessening the power requirements of any one. The strategy would require lightning-quick, high-bandwidth fiber connections. But it’s technically doable, and Google Gemini Ultra’s training run is an early example.
All told, Epoch suggests a range of possibilities from 1 gigawatt (local power sources) all the way up to 45 gigawatts (distributed power sources). The more power companies tap, the larger the models they can train. Given power constraints, a model could be trained using about 10,000 times more computing power than GPT-4.
Chips: Does It Compute?
All that power is used to run AI chips. Some of these serve up completed AI models to customers; some train the next crop of models. Epoch took a close look at the latter.
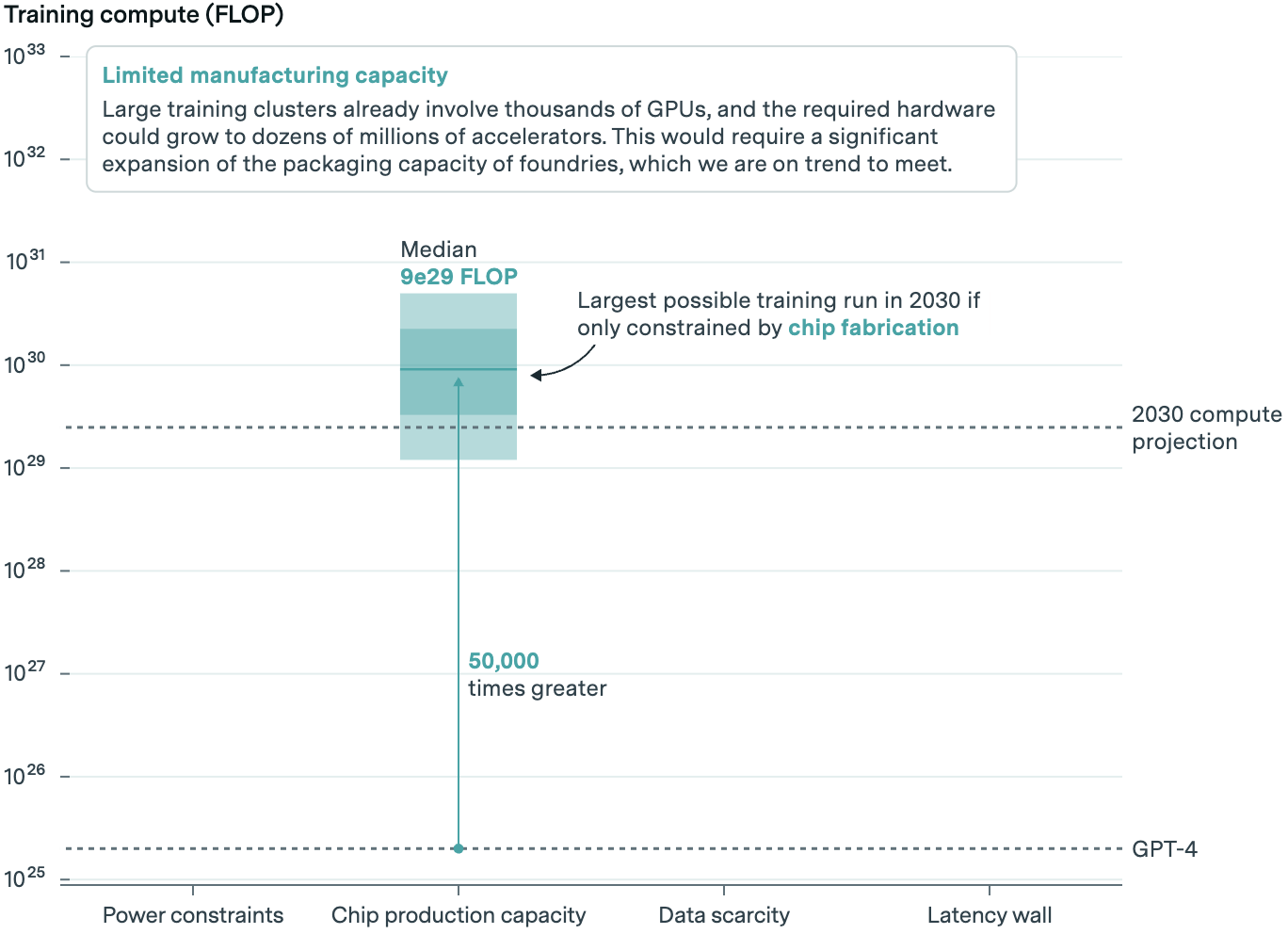
AI labs train new models using graphics processing units, or GPUs, and Nvidia is top dog in GPUs. TSMC manufactures these chips and sandwiches them together with high-bandwidth memory. Forecasting has to take all three steps into account. According to Epoch, there’s likely spare capacity in GPU production, but memory and packaging may hold things back.
Given projected industry growth in production capacity, they think between 20 and 400 million AI chips may be available for AI training in 2030. Some of these will be serving up existing models, and AI labs will only be able to buy a fraction of the whole.
The wide range is indicative of a good amount of uncertainty in the model. But given expected chip capacity, they believe a model could be trained on some 50,000 times more computing power than GPT-4.
Data: AI’s Online Education
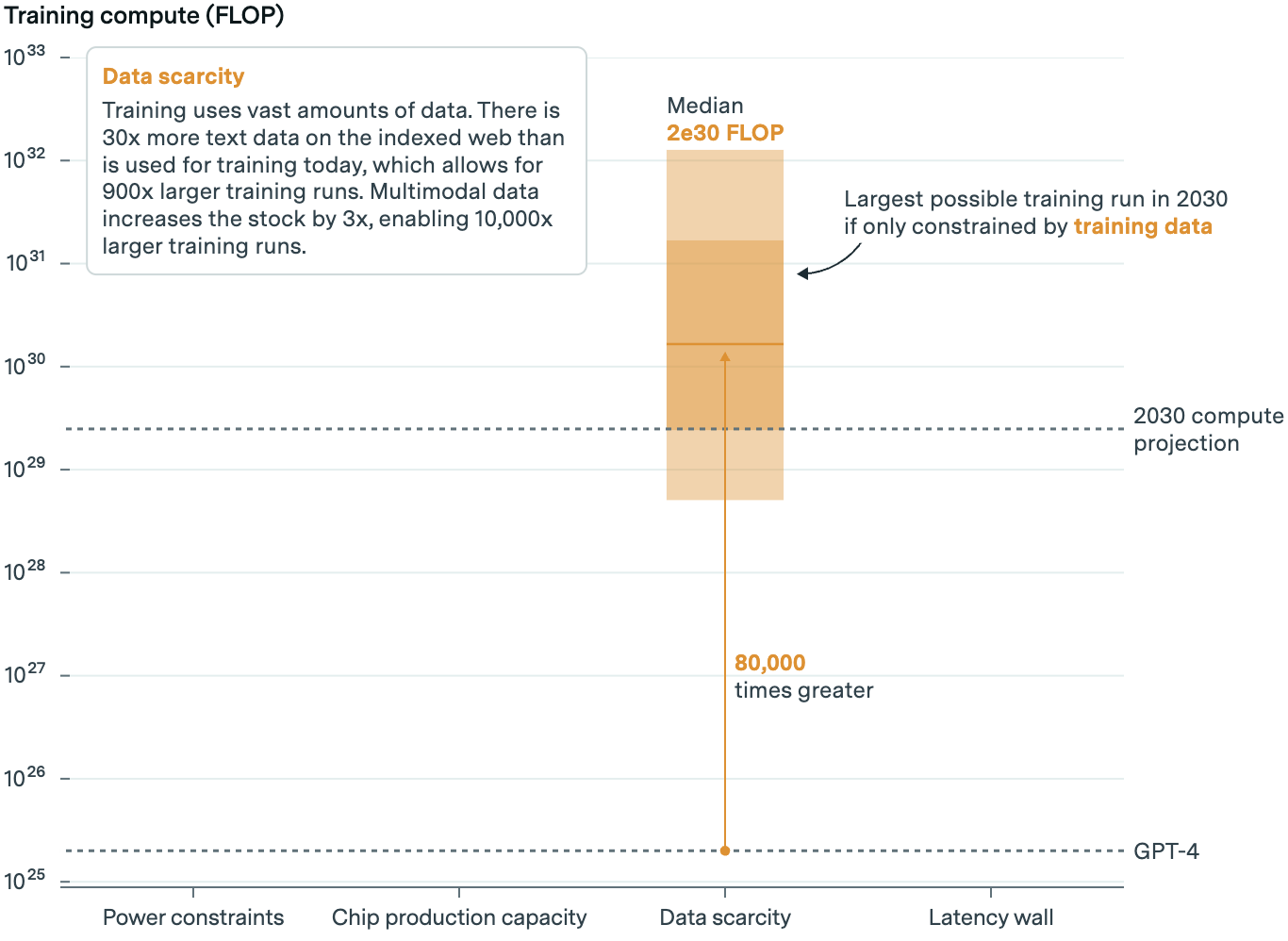
AI’s hunger for data and its impending scarcity is a well-known constraint. Some forecast the stream of high-quality, publicly available data will run out by 2026. But Epoch doesn’t think data scarcity will curtail the growth of models through at least 2030.
At today’s growth rate, they write, AI labs will run out of quality text data in five years. Copyright lawsuits may also impact supply. Epoch believes this adds uncertainty to their model. But even if courts decide in favor of copyright holders, complexity in enforcement and licensing deals like those pursued by Vox Media, Time, The Atlantic and others mean the impact on supply will be limited (though the quality of sources may suffer).
But crucially, models now consume more than just text in training. Google’s Gemini was trained on image, audio, and video data, for example.
Non-text data can add to the supply of text data by way of captions and transcripts. It can also expand a model’s abilities, like recognizing the foods in an image of your refrigerator and suggesting dinner. It may even, more speculatively, result in transfer learning, where models trained on multiple data types outperform those trained on just one.
There’s also evidence, Epoch says, that synthetic data could further grow the data haul, though by how much is unclear. DeepMind has long used synthetic data in its reinforcement learning algorithms, and Meta employed some synthetic data to train its latest AI models. But there may be hard limits to how much can be used without degrading model quality. And it would also take even more—costly—computing power to generate.
All told, though, including text, non-text, and synthetic data, Epoch estimates there’ll be enough to train AI models with 80,000 times more computing power than GPT-4.
Latency: Bigger Is Slower
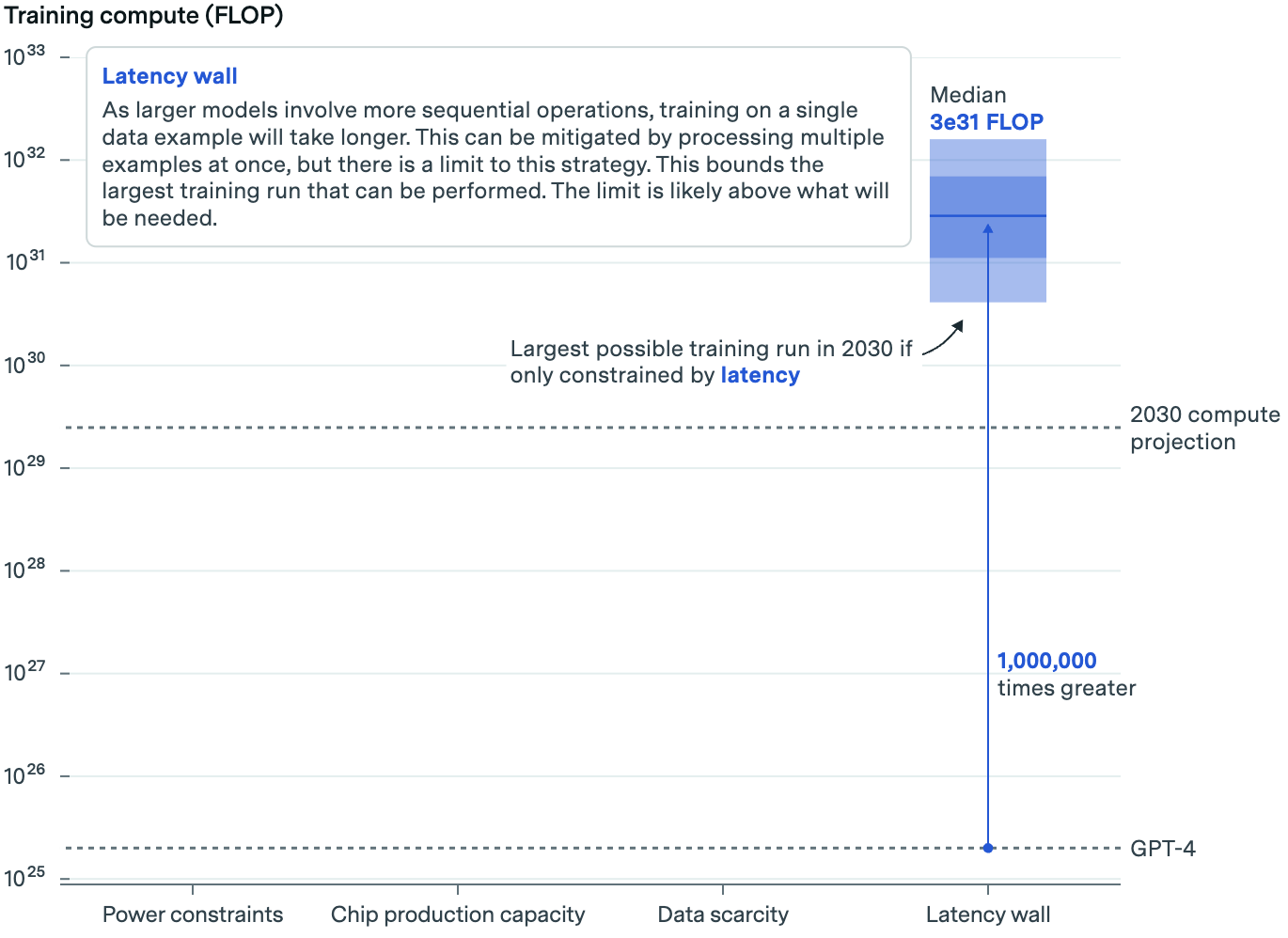
The last constraint is related to the sheer size of upcoming algorithms. The bigger the algorithm, the longer it takes for data to traverse its network of artificial neurons. This could mean the time it takes to train new algorithms becomes impractical.
This bit gets technical. In short, Epoch takes a look at the potential size of future models, the size of the batches of training data processed in parallel, and the time it takes for that data to be processed within and between servers in an AI data center. This yields an estimate of how long it would take to train a model of a certain size.
The main takeaway: Training AI models with today’s setup will hit a ceiling eventually—but not for awhile. Epoch estimates that, under current practices, we could train AI models with upwards of 1,000,000 times more computing power than GPT-4.
Scaling Up 10,000x
You’ll have noticed the scale of possible AI models gets larger under each constraint—that is, the ceiling is higher for chips than power, for data than chips, and so on. But if we consider all of them together, models will only be possible up to the first bottleneck encountered—and in this case, that’s power. Even so, significant scaling is technically possible.
“When considered together, [these AI bottlenecks] imply that training runs of up to 2e29 FLOP would be feasible by the end of the decade,” Epoch writes.
“This would represent a roughly 10,000-fold scale-up relative to current models, and it would mean that the historical trend of scaling could continue uninterrupted until 2030.”
What Have You Done for Me Lately?
While all this suggests continued scaling is technically possible, it also makes a basic assumption: That AI investment will grow as needed to fund scaling and that scaling will continue to yield impressive—and more importantly, useful—advances.
For now, there’s every indication tech companies will keep investing historic amounts of cash. Driven by AI, spending on the likes of new equipment and real estate has already jumped to levels not seen in years.
“When you go through a curve like this, the risk of underinvesting is dramatically greater than the risk of overinvesting,” Alphabet CEO Sundar Pichai said on last quarter’s earnings call as justification.
But spending will need to grow even more. Anthropic CEO Dario Amodei estimates models trained today can cost up to $1 billion, next year’s models may near $10 billion, and costs per model could hit $100 billion in the years thereafter. That’s a dizzying number, but it’s a price tag companies may be willing to pay. Microsoft is already reportedly committing that much to its Stargate AI supercomputer, a joint project with OpenAI due out in 2028.
It goes without saying that the appetite to invest tens or hundreds of billions of dollars—more than the GDP of many countries and a significant fraction of current annual revenues of tech’s biggest players—isn’t guaranteed. As the shine wears off, whether AI growth is sustained may come down to a question of, “What have you done for me lately?”
Already, investors are checking the bottom line. Today, the amount invested dwarfs the amount returned. To justify greater spending, businesses will have to show proof that scaling continues to produce more and more capable AI models. That means there’s increasing pressure on upcoming models to go beyond incremental improvements. If gains tail off or enough people aren’t willing to pay for AI products, the story may change.
Also, some critics believe large language and multimodal models will prove to be a pricy dead end. And there’s always the chance a breakthrough, like the one that kicked off this round, shows we can accomplish more with less. Our brains learn continuously on a light bulb’s worth of energy and nowhere near an internet’s worth of data.
That said, if the current approach “can automate a substantial portion of economic tasks,” the financial return could number in the trillions of dollars, more than justifying the spend, according to Epoch. Many in the industry are willing to take that bet. No one knows how it’ll shake out yet.
Image Credit: Werclive  / Unsplash
/ Unsplash
* This article was originally published at Singularity Hub





0 Comments